Privacy vulnerabilities in mechanisms designed to improve privacy are not something expected. On the contrary, they are the last place where you’d expect a privacy bug.
Intelligent Tracking Prevention (ITP) is an impressive feature of Safari, the default browser used on iPhones, iPads, and Macs. It was the first broadly deployed mechanism aiming to reduce invasive web tracking and other privacy abuses. If you browse this site using Apple’s devices, ITP is on by default. I think we’ll agree that while privacy is good, and privacy by default is even better.
ITP vulnerability
It so happened that the design of Intelligent Tracking Prevention was found to allow user tracking, fingerprinting, and disclosing Safari users’ browsing history on Macs and iPhones. It’s the beginning of 2020, but I feel safe saying that this stuff is among the most important privacy works this year. Today such bugs are very rare (and generally do not happen).
ITP detects and blocks tracking on the web. When you visit a few websites that happen to load the same third-party resource, ITP detects the domain hosting the resource as a potential tracker and from then on sanitizes web requests to that domain to limit tracking. Tracker domains are added to Safari’s internal, on-device ITP list. When future third-party requests are made to a domain on the ITP list, Safari will modify them to remove some information it believes may allow tracking the user (such as cookies). To understand the ITP vulnerability found by Google researchers, and this post, that is all we need.
When Apple published information about its fixes for the issues (“preventing tracking prevention tracking”), some people suspected what may be at the center of the issue. The WebKit blog post acknowledges that the fundamental weakness of ITP-like technology is that such features introduce global state in the web browser. Until now no details about the problem had been posted to the public. This changed when a group of Google researchers published their research earlier today. To quote them:
“Any site can issue cross-site requests, increasing the number of ITP strikes for an arbitrary domain and forcing it to be added to the user’s ITP list. By checking for the side effects of ITP triggering for a given cross-site HTTP request, a website can determine whether its domain is present on the user’s ITP list; it can repeat this process and reveal the ITP state for any domain.”
Any website on the internet can also deliberately take advantage of this. Why would a website want to reveal the contents of a user’s ITP list or tamper with its contents?
The details should come as a surprise to everyone because it turns out that ITP could effectively be used for:
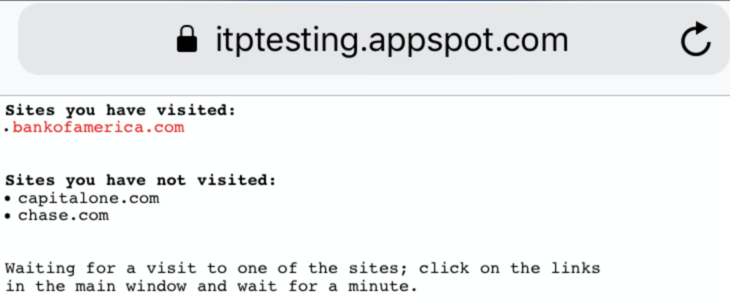
- information leaks: detecting websites visited by the user (web browsing history hijacking, stealing a list of visited sites)
- tracking the user with ITP, making the mechanism function like a cookie
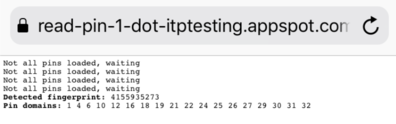
- fingerprinting the user: in ways similar to the HSTS fingerprint, but perhaps a bit better
I am sure we all agree that we would not expect a privacy feature meant to protect from tracking to effectively enable tracking, and also accidentally allowing any website out there to steal its visitors' web browsing history. But web architecture is complex, and the consequence is that this is exactly the case. Bugs happen, this one hopefully fixed.
By visiting an attacker-controlled website that would include attacker-chosen content, the attacker can fool the ITP classifier to add it to the list, so remember it. Once a tracker is “included” in the ITP list, it also becomes detectable. All this combined means that the attacker has a read-write access to ITP state, which can be used to mount privacy attacks. Some of the used approaches are quite clever so I recommend reading the full disclosure and inspecting the proof of concepts.
Now, the researchers posted proof of concepts, which no longer work on iOS 13.3 (it contains a fix from December). But it turns out they do work on iOS 12.4.4, with latest patches (from December). Using my testing “old” iPhone 6 (that never got a 13.x update) I confirm that all of the claimed privacy attacks work in practice.
The image below shows how it was/is possible to discover what sites the user (here: myself) visited:
The proof of concepts shows also how to assign/detect fingerprints:
Using the design of ITP for tracking and leaking information is unexpected. Because the exploit takes advantage of the design of ITP itself (a systemic issue, not a coding mistake), a natural question may arise if the released updates are sufficient. I reckon that in Apple’s view this is the case, hence the public hint towards the existence of the bug and announcing the mitigations in the original 10 December blog post. Curiously, I fail to see a definitive answer about whether the issues have been fully fixed either in the Apple writeup or in the details published by the researchers.
Was it used in practice?
An interesting question, but we don’t know. I don’t think so because this technique was simply not broadly known (and it takes time to operationalise these kind of things). However, this tracking vector was certainly usable. It is also clear that potentially parties interested in doing so exist, as some previously also used non-standard measures like HSTS fingerprinting to bypass ITP.
We should be thankful to original discoverers for taking the time to investigate the full potential of the ITP issue, but also for the fact of later transparently disclosing information. Without having access to detailed insight into how the bug works, with full risks listed, it would be very difficult to understand the true potential. In the long term, those extra transparency steps should benefit the community that researches or builds privacy features and who deal with privacy engineering daily. Maybe we can extract systemic insight from it (authors do not speak about that).
Assessing security & privacy impact
For me, this is especially fascinating, as I am also involved in security and privacy research & analysis of the web for a while now. In 2017 we released a methodology of assessing privacy aspects of web browser features (PDF), highlighting the extra care steps that might be handy. Studying the privacy impact of new web features is important (see also some of my previous analyses, like the persistent web apprehension or web bluetooth privacy).