Digital web advertising is an ecosystem undergoing strategic changes. Google’s Privacy Sandbox is promising to redesign web advertising technology in ways that will respect user’s privacy, including based on some previous designs. Detailed technically-enabled analysis should wait until more design features are known.
In this post I focus on a single privacy issue related to Federated Learning of Cohorts (FloC). FloC feature desire to deliver unique-enough IDs assigned to “cohorts” of users. Similar/identical ID is assigned to users with similar interests, as judged by the history of browsed websites. This data is SimHashed to obtain a fingerprint based on web browsing history. The way it works is simple. Each call to document.interestCohorts() results in data describing the cohort ID {id: "498413426628", version: "chrome.1.0"}, where the ID “498413426628” is loosely based on the user's web browsing history.
There are of course questions of privacy design. For example, which sites should be included in such a computation (sensitive sites should not be used, hopefully). Many other privacy design considerations should be considered, such as the minimum/maximum number of websites to consider, and their competition, the nature of the sites, whether subpages are considered or not, how frequently the ID is updated (current assumption: 7 days), and so on.
Such design choices may have a dramatic impact on the privacy standing of a final product. Analysis of this is far from simple. The final technical privacy analysis is deferred until Google Chrome team releases their privacy protection techniques (they appear not to be enabled during the current tests), or at least I do not see them.
An initial look at FloC
FloC is currently in a testing phase (not enabled for all users) so to test this enabling of the feature explicitly is necessary. This can be done by starting the web browser from a command line with --enable-features=InterestCohortAPI arguments (in Chrome 89).
Privacy bug - incognito mode detection
One thing I can already spot as a privacy issue. Unfortunately, it seems that FloC contains a privacy design bug that leaks the information about whether the user is browsing in private mode (incognito) or not (some time ago I spotted a similar incognito detection bug in another API).
Detecting this deterministically is straight-forward. I set up a demonstration here.
This information leak works because when browsing in incognito a call to document.interestCohort() results in an exception: “Uncaught DOMException: Failed to get the interest cohort: either it is unavailable, or the preferences or content settings has denined the access.” (severity is elevated due to the typo “denined”!).
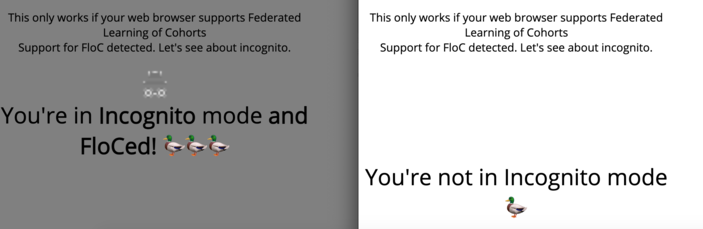
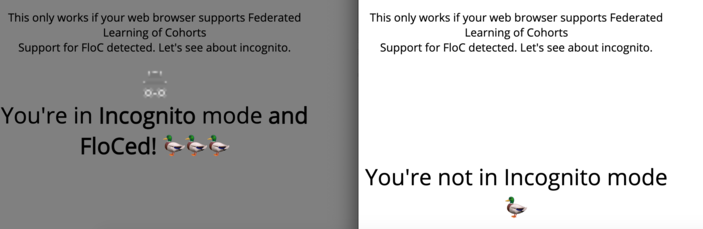
While indeed, the private data about the FloC ID is not provided (and for a good reason), this is still an information leak. Apparently it is a design bug because the behavior seems to be foreseen to the feature authors. It allows differentiating between incognito and normal web browsing modes. Such behavior should be avoided.
How to solve such design issues?
An interesting question is how to solve such an information leak. Obviously if FloC is unavailable in incognito mode by design then this allows the detection of users browsing in private browsing mode.
An alternative solution could be to return random values when a call to interestCohort() is made. But this approach would allow detecting the bogus data by comparing the results of several calls to the function made consecutively.
Perhaps one alternative could be the computation of a random ID upon the start of the web browser? However, then such random ID data would constitute a short-term fingerprint (like the IP address and the user-agent string, or the cohort ID in non-private mode).
Ultimately some decisions need to be made but this nice mental exercise shows that design decisions of this kind are not so simple and have consequences. Such is the nature of privacy engineering and design. Designing and communicating things with security or privacy consequences is not simple.
Summary
In this post, I had an initial look at one component of Google’s Privacy Sandbox, the federated learning of cohorts. I focus on a particular privacy bug, a leak of information about browsing in private mode. It’s a simple demonstration but the design of such sensitive features is ultimately a question of strategy and trust.
Did you like the assessment and analysis? Any questions, comments, complaints, or offers for me? Feel free to reach out: me@lukaszolejnik.com