The user’s Web browsing history is usually defined as a list of websites the user has visited, such as “google.com, facebook.com, reddit.com, bbc.co.uk, random-site.org, etcetc.org.uk”. On its own, it may seem innocuous. It turns out browsing history can be processed to extract insight about the user (or tracking the user).
Web browsing history is sensitive
Web browsing histories are quite sensitive. They convey rich information about the user, to the level of possibility of extracting psychometric or demographic insight. They are not subject to significant changes over time (i.e. stable due to often fixed preferences). They are unique to the user (users generally tend to browse a specific bunch of sites conforming to their interests). In some ways, browsing history resemble biometric-like data due to their uniqueness and stability. If this rings a bell like it’s possible to single-out individuals out of many, it is justified. Because this is the General Data Protection Regulation’s technical litmus test whether something is personal data:
(26) (...) To determine whether a natural person is identifiable, account should be taken of all the means reasonably likely to be used, such as singling out, either by the controller or by another person to identify the natural person directly or indirectly. (...)
When the data allows singling out individuals, this data automatically comes under this regulation, the GDPR.
If web browsing histories in certain contexts may now constitute sensitive personal data it would change a lot. But how did we arrive here? Thanks to some research work.
Web browsing histories are unique
In 2009-2011 we did some research work motivated with a positive aim of educating web users about certain risks of browsing history leaks. The pointed to a perhaps unexpected conclusion. It indicated that web browsing histories may be unique to the user. In our study, the number of unique user fingerprints revealed by observing the set of visited websites was as much as in 97% of cases. Furthermore, such fingerprints were stable over time (in 38% of analyzed cases). We also found that limiting to just 50 most popular sites, the uniqueness was still substantial.
That was the early 2010s. In 2020 the situation is different. Today, user’s private data are processed at an order of magnitude greater scale than in 2010. Fortunately, someone verified that the result holds.
Confirmed - Web browsing histories are unique
It turns out that our initial indicative work is now significantly upheld by recent (2020) research from Mozilla (by Sarah Bird, Ilana Segall, and Martin Lopatka) that has replicated our original study, using very refined data. This work provides an even more stringent assessment of how sensitive the list of user-visited sites really is. The case is stronger, which should be a call to action for many.
The team inspected the evolution of web browsing history fingerprints for around 52,000 Firefox users, for two weeks. Such collected data offered the potential for deep analysis. It allows making strong, well justified claims indeed.
The uniqueness rate of the web browsing history, using methods similar to ours, turned out to be 99%. They indicate that users can be reidentified via such a fingerprint, in 80% cases. Such numbers are shockingly high.
That’s not all. The work by the Mozilla team fully confirmed some of our previous insights. For example that considering the 50 most popular sites only is sufficient to obtain unique fingerprints. Furthermore, the work extends our previous studies in interesting ways.
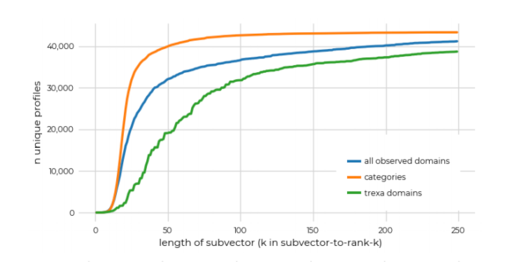
I’m particularly happy with the stringent assessment considering the differences between web browsing histories of various users when analyzed as a fingerprint:
We believe that our results strengthen the original paper’s claim that subsets of user data pose a potential for exploitation in user identifiability
The authors replicated also the theoretical potential for third-party resource providers (i.e. trackers) to reidentify users based on web browsing history fingerprints. This unsurprisingly shows that the big actors (i.e. Google/Alphabet, Facebook, etc.) have a privileged position.
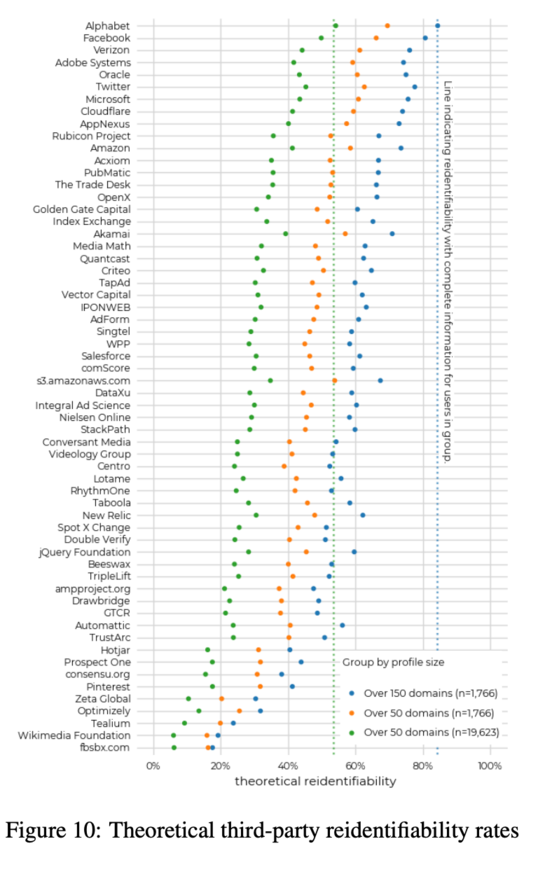
The image nicely shows the potential to reidentify users based on web browsing history analysis. It is suggestive, showing the capability of some of the biggest web companies.
Practical impacts
Web browsing histories are private data, and in certain contexts, they are personal data. Now the state of the art in research indicates this. Technology should follow. So too should the regulations and standards in the data processing. As well as enforcement.
Meanwhile, lists of user-visited web sites are processed on a rather massive scale. All websites log user visits. Some aggregating actors (Google, Facebook, etc?) log even more, not to mention the third-party advertisers. Lists of user-visited sites are even transferred to advertisers programmatically via the real-time bidding channel (1, 2). The amount of web browsing data available to website operators and advertisers has only increased over the past decade.
Summary
I commend the Mozilla team for tackling this unpopular and unobvious problem that is not much spoken of, and so far did not catch the interest of academics, yet nonetheless it was and is of obvious practical relevance. Both in 2011 and in 2020.
The research in this domain just moved the state of the art much forward. It should be transformative. It is of practical importance to many - the users, the advertisers, the web platforms, organizations tasked with consumer protection, as well as data protection authorities, who so far appear to have decided to look elsewhere.
Web browsing histories are personal data. Deal with it.
Also, it feels quite great to have one’s work replicated after about 10 years!
Our findings on profile uniqueness replicate those of Olejnik et al. and our work on reidentifiability provides robust evidence for the viability of browser profiles as a tracking identifier.
Did you like the assessment and analysis? Any questions, comments, complaints or maybe even offers? Feel free to reach out: me@lukaszolejnik.com