European Union is on a route to simplify regulations. Some measures in the past decade have been criticised as overbroad. European Commission plans to modify the General Data Protection Regulation.
Some of the changes are great, and may limit existing lack of clarity and simply useless things, or at least unfortunate. The changes go quite far, but many are sensible. They include altering the very definition of personal data which has been the cornerstone of European data protection for decades. In this post I make a technical, policy and regulatory assessment. The full proposal is here.
Change of PERSONAL DATA definition.
Article 4(1) on personal data definition becomes entity‑relative
“Information relating to a natural person is not necessarily personal data for every other person or entity, merely because another entity can identify that natural person. Information shall not be personal for a given entity where that entity cannot identify the natural person to whom the information relates, taking into account the means reasonably likely to be used by that entity. Such information does not become personal for that entity merely because a potential subsequent recipient has means reasonably likely to be used to identify the natural person to whom the information relates”
This clarifies that for example a small shop or a restaurant need not be over-paranoid about hypotheticals it cannot foresee or control. There is broad agreement that information is not personal data merely because another entity can identify the person. A breach in other systems does not automatically affect separate controllers. However this wording does not match the approach of the Court of Justice of the European Union, which assesses identifiability by reference to means which may reasonably be used to identify the data subject, including with the assistance of other persons, by the controller or by any other person as in case C-582/14.
The entity relative formula reduces scope because it ignores third party means, which narrows protection. In practice controllers could argue they lack means they could in fact obtain or use.
Example
An adtech platform receives email hashes that data brokers can trivially match. Today those hashes are personal data if identification is reasonably likely using means available to the controller or to others. Under the official proposal the platform could try to declare them non personal because its own means are insufficient even though matching is easy for partners or even for itself with reasonable effort. Even with unique salts they remain personal data if the platform can use a lookup table or resubmit raw emails it holds elsewhere to generate the same hash and match. Under the official wording the platform can argue the same hashes are not personal for it if it cannot identify using its own means while ignoring partners capabilities.
Currently identifiability under GDPR and CJEU case law considers third party means. The official proposal makes identifiability entity relative for the given entity. That is a big difference.
Training AI with special-category data is fine, IF…
“For processing referred to in point (k) of paragraph 2, appropriate organisational and technical measures shall be implemented to avoid v the collection and otherwise processing of special categories of personal data. Where, despite the implementation of such measures, the controller identifies special categories of personal data in the datasets used for training, testing or validation or in the AI system or AI model, the controller shall remove such data. If removal of those data requires disproportionate effort, the controller shall in any event effectively protect without undue delay such data from being used to produce outputs, from being disclosed or otherwise made available to third parties”
In effect, this would create a certain tolerance for residual special-category data in training sets, subject to avoidance, removal, or isolation attempts where removal is a disproportionate effort. The goal here is to offer guarantees to AI developers, so allow this with a caveat. In other words, training on AI on special category data (health, political opinions, religion, sexual orientation, etc.) is allowed, if the above is met.
In other words, if you are developing/operating an AI system or AI model (as defined in the AI Act), you may process special-category data when its presence is merely residual/incidental in training, testing, validation, or within the model/system itself. Lawful basis is still necessary. It’s also necessary to 1) implement organisational/technical measures to avoid, to the greatest possible extent, collecting or otherwise processing special-category data; 2) if detected, remove such data from datasets/models; 3) if removal would require disproportionate effort (e.g., re-training that is not feasible immediately), you must effectively protect the data so it cannot be used to produce outputs and cannot be disclosed/made available to third parties.
Biometric verification under sole control (Article 9 paragraph 2 point l)
“processing of biometric data is necessary for the purpose of confirming the identity of a data subject (verification), where the biometric data or the means needed for the verification is under the sole control of the data subject.”
On‑device processing would be explicitly allowed. This is fine (and a good change).
Pseudonymisation is going to be useful (Article 41a), finally.
“Article 41a. The Commission may adopt implementing acts to specify means and criteria to determine whether data resulting from pseudonymisation no longer constitutes personal data for certain entities.
For the purpose of paragraph 1 the Commission shall:
- assess the state of the art of available techniques;
- develop criteria and/or categories for controllers and recipients to assess the
risk of re-identification in relation to typical recipients of data. The implementation of the means and criteria outlined in an implementing act may be used as an element to demonstrate that data cannot lead to reidentification of the data subjects.”
This is promising (great!). Currently pseudonymisation in the GDPR is quite… useless for the controller, as there’s no direct, clear incentive to do so. This point would now allow the development and deployment of innovative privacy-preserving technologies, which are already mature. However, the details must be clarified. But that’s the best addition in this GDPR modification. It can allow processing in ways that protect user data and privacy. It would also UNLOCK some creative uses of data done the right way.
AI processing done via legitimate interests
On a literal reading of the Commission’s proposal (new Art. 88c), controllers may rely on legitimate interests for AI training/operation, i.e., without consent where no other EU or national law explicitly requires it, provided that they pass the balancing test and implement the built-in safeguards (enhanced transparency and an unconditional right to object, plus source/training/testing minimisation and controls against residual memorised data). For special-category data this does not open a general route to use such data.
The closed list when identifiers are OK
The official text moves personal data processing on or from terminal equipment (e.g. web browser) into the GDPR via a closed purpose list (Article 88a). If an operation is strictly necessary solely for one of these four purposes, consent is not required. The text says processing is permitted if it is necessary only for one of the following purposes:
- Transmission of an electronic communication over an electronic communications network.
- Providing a service explicitly requested by the data subject.
- Creating aggregated information to measure the audience of an online service, where it is carried out by the controller of that service solely for its own use.
- Maintaining or restoring the security of the controller’s service requested by the data subject, or the terminal equipment used for providing that service.
The draft also draws a red line on further use: where the controller collects personal data solely for the above purposes, it may not reuse the data for any other purpose unless provided for by Union or Member State law.
Two UX obligations from the official text:
- when relying on consent under, the data subject must be able to give or refuse with a single-click (or equivalent), and a refusal must be respected for at least six months with no re-ask for the same purpose in that period.
- when relying on legitimate interests for direct marketing, the data subject must be able to object with a single-click.
Cookie/ID consent notices
The “cookie law” (ePrivacy Article 5(3)) does not apply where information constitutes personal data or leads to the processing of personal data and the operation on or from terminal equipment is carried out in accordance with GDPR Article 88a. In that case, GDPR governs. If the information does not constitute or lead to personal data, ePrivacy Article 5(3) continues to apply.
Consent remains necessary for storage/access that does not constitute and does not result in processing of personal data (unless strictly necessary for a service explicitly requested by the user).
- When consent is needed: storage or access on terminal equipment is not strictly necessary for one of the four purposes, transmission, a service explicitly requested by the person, the provider’s own aggregated audience measurement, or security, and there is no valid machine-readable consent signal already set for the same purpose. And for non-personal storage/access unless it is strictly necessary for a service explicitly requested by the user.
- When consent is not needed: when the operation is strictly limited to transmission, a service explicitly requested by the person, the provider’s own aggregated audience measurement, or security (with no repurposing), or when a compliant machine-readable consent signal already covers the same purpose.
Silly consent user experience is GONE
Let me just say that I know what I’m talking about, being “in the business” for long. I was also advising on the previous attempt (ePrivacy Regulation change; which failed). Hot take: this is really promising! The modified GDPR implements fully what I recommended several years ago - use the web browser as the means trusted by the user, to mediate consent.
If consent is necessary, the proposal demands two design rules. Users must be able to give consent or refuse in an easy, intelligible way with a single-click button or equivalent means, and the controller must respect that choice for at least six months with no new request for the same purpose in that period.
The proposal also adds a duty to recognise standardised, machine-readable signals encoding consent/refusal and the right to object to direct marketing; controllers must be able to interpret and respect those indications.
Literally: “(46) Data subjects should have the possibility to rely on automated and machine-readable indications of their choice to consent or refuse a consent request or object to the processing of data. Such means should follow the state of the art. They can be implemented in the settings of a web browser or in the EU Digital Identity Wallet as set out by Regulation (EU) 914/2014, or any other adequate means. Rules set out in this Regulation should support the emergence of market-driven solutions with appropriate interfaces. The controller should be obliged to respect automated and machine-readable indications of data subject’s choices once there are available standards. In light of the importance of independent journalism in a democratic society and in order not to undermine the economic basis for that, media service providers should not be obliged to respect the machine-readable indications of data subject’s choices. The obligation for providers of web browsers to provide the technical means for data subjects to make choices with respect to the processing should not undermine the possibility for media service providers to request consent by data subjects”
That’s welcome, though the reference to the EU Digital Identity Wallet is puzzling—why it should interact with online ads infrastructure is unclear.
There is a limited carve-out: the obligation to interpret and respect machine-readable indications does not apply to media service providers while they are providing a media service.
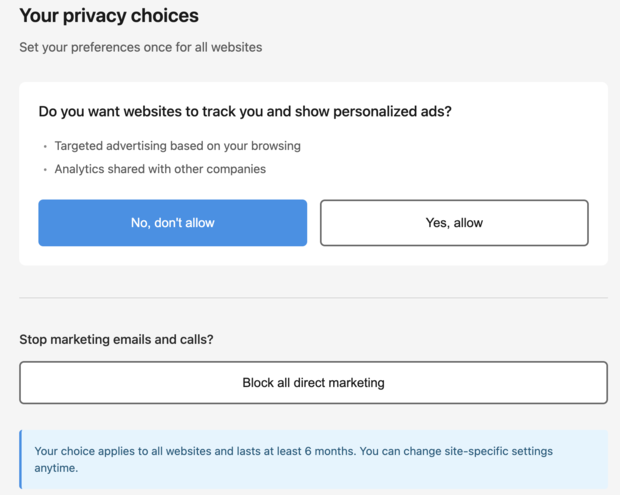
What this means in practice
If a website sets a session cookie or otherwise uses an ID strictly for a shopping cart, consent is not needed.
If the website measures its own audience using aggregated information and keeps it solely for its own use, no consent is needed.
If third-party analytics or ad technology builds cross-service profiles, it falls outside the four permitted purposes. Consent may be required. The site must respect any standardised consent or refusal signals once the standards exist and the applicable implementation window has passed. This implies browser-level implementations (and, where available, extensions) that deliver such signals, with full support in law. That would make the long-mocked W3C Do Not Track (Tracking Preference Expression) relevant again, or its successors. It’s unclear whether the California GPC would be a proper choice in the EU. A local standard will likely be favoured, though there’s room for creativity.
For example, it could be an HTTP header like this:
GDPR-Consent: ver=1; action=refuse; purposes=ads,third_party_analytics; scope=global; exp=2026-11-19T00:00:00Z; source=browser; policy=eu-88b-2026; comment=byebye```Keep in mind this will be subject to market competition, so whichever approach is better will win.
Summary
Brussels says it’s simplifying the GDPR. The draft looks strong in places and does good things in others. It narrows cookie consent/banner reliance to a tight first-party lane and shifts many prompts to device-level signals.
Consent isn’t removed, but rationalised. It can be granted via OS, web browser, or extension once standards exist, and sites must accept those signals. The technology layer will carry this, making consent a user interface issue rather than paperwork, or a box-click nightmare.
Expect more from me in this area.
Comments, queries, or maybe contract offers? ;-) Contact me at me@lukaszolejnik.com. Let's talk!