The European Commission is preparing to compel Google to stream search data to third-party companies through an automated API. It is doing this under the Digital Markets Act, a regulation with a sound goal of improving competition in digital markets. But this specific proposal would have the effect of exposing the EU users' individual Google search queries to unspecified companies that users have no knowledge of, or control over.
Unless the EC corrects the proposal, it will amount to one of the largest mandated transfers of sensitive user data in Europe in decades, making the privacy problem immediate and sizeable. Receiving access to this data would be very easy for other companies, requiring them only to jump through bureaucratic and procedural hoops, rather than ensuring that the shared data is properly anonymized and aggregated to prevent harm to users (the EC has proposed some measures on this front, but they are woefully inadequate, as discussed at length in this post). This immediately creates a national-security problem because once this feed is available to qualifying third parties, all a hostile foreign intelligence service needs to do to gain detailed intelligence on the individual searches of all EU citizens is to obtain access through a formally compliant search engine, AI-search wrapper, a mock AI chatbot, or funded front company. Pulling this off is very easy, even easier than registering a bogus company to access Real-Time Bidding data from Google in 2015, back when nobody cared about security and privacy of this layer.
My 15+ yr experience lets me confidently ring an alarm bell here. It’s a privacy and a national and international security risk. One of the biggest risks in Europe this year.
What data is being handed over
The proposal does not merely open access to abstract statistics or aggregate market data. It requires Google to offer an API-based, reliable and stable daily feed of essentially all search records from people in Europe, including what they search for, what results they see, what they click, how they refine their searches, and where those searches roughly originate.
The draft requires sharing of the user’s entire search query, timestamp, coarse but useful location data, query language, device identifier, timing and order of clicks, hover, scroll, swipe, expansion events, the full sequence of query, view, click, and ranking data associated with a user over time, and much more. In this post I focus on the query string and the mechanics of its delivery.

Needless to say, search queries are deeply private data, often tied to users’ sensitive secrets, such as medical conditions, sexual preferences, relationships, and many other kinds of information that users do not expect to be shared, especially with random entities and in bulk. At this scale, weak anonymisation does not merely create a residual privacy risk - it is likely to enable persistent tracking and surveillance of people, places, institutions, and events across Europe.
That makes it absolutely critical for any approach that results in sharing such data to provide strong privacy that prevents linkability, deanonymization, and other uses of the data that would undermine users’ privacy expectations. The Commission is proposing a filtering scheme based on entity allowlists, query-length thresholds, metadata generalisation, and contractual controls. For this kind of data, at this volume, with daily record-level delivery to multiple third parties, that approach is currently not adequate. It is simply not enough. It treats search data as if privacy can be guaranteed by hand-waving about what the intended uses of data should be, rather than understanding what they really are.
How would the "sanitization" methods work?
The proposed sanitisation system removes direct identifiers such as account IDs, IP addresses, device IDs, and precise timestamps from the search record. It strips parts of viewport geometry, replaces image-only queries with placeholders, bins click-back time into coarse intervals, and then applies three gates.
The proposal requires an allowlist to be built from the parts of search queries. If part of a query is detected as personal data, such as a name, address, or phone number, it is grouped into one entity. Everything else is split into ordinary words.
The system counts how many unique signed-in European Economic Area users searched for each entity or word during the previous 13 months. If more than 50 signed-in users searched for it, that entity or word is added to the allowlist for five years. Note that this restriction applies to individual entities, not the entire query - a unique search query made of common words would not be protected.
When data is later released to other companies, a modified query passes the entity test only if every part of the query is on that allowlist. It must also pass a separate length test. The query has to be shorter than the weekly threshold calculated for that language.
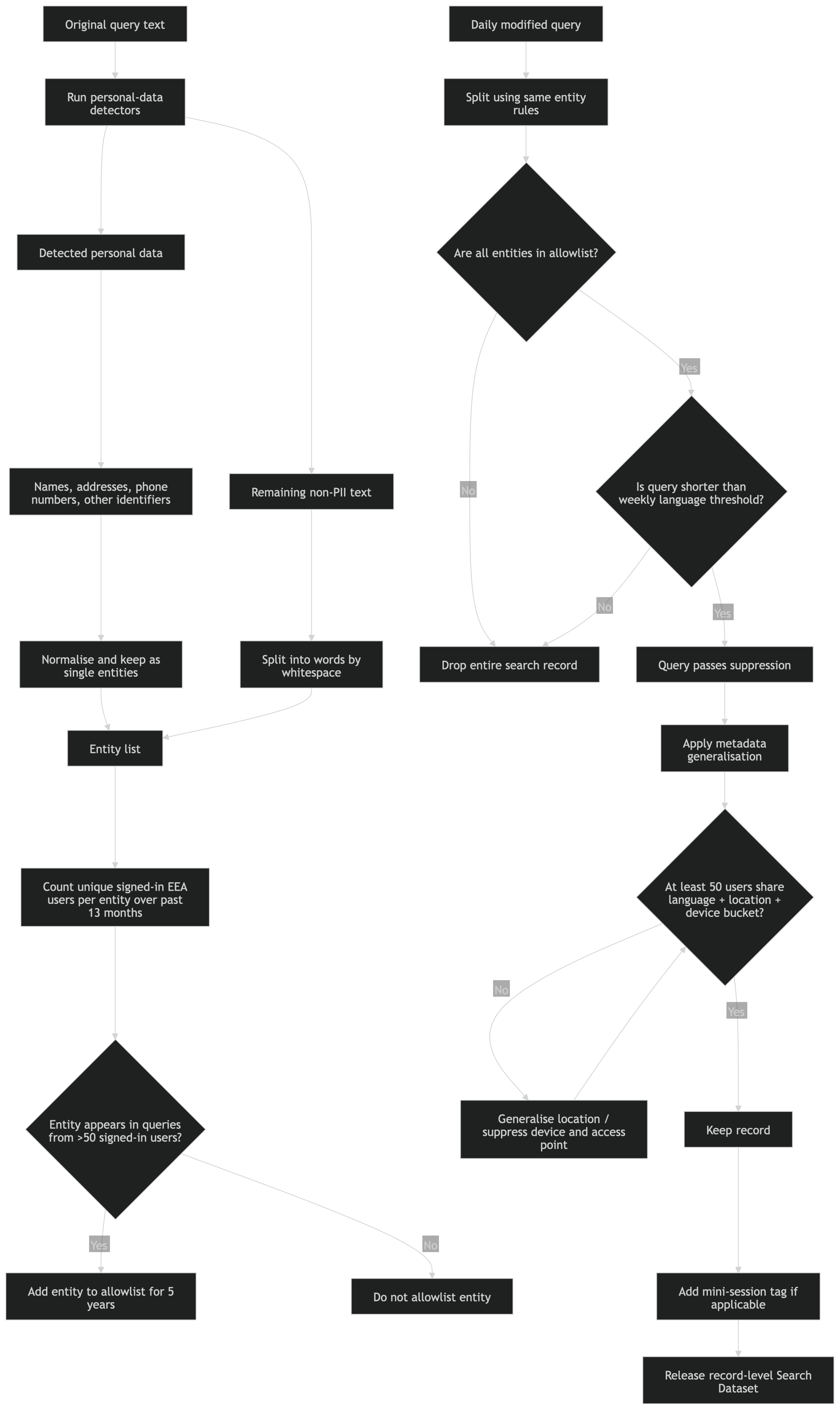
Example entity split:
("john doe", "200 wetstraat brussel", "04 12 34 56 78", "communications", “department")
A query is released if every entity in the modified query is in the allowlist and the full query is below that length threshold. There is no requirement that the full query itself has been issued by multiple users. The system ensures that each individual component of the query (either a word, or personal data such as name or address), then releases the record.
Example evaluation:
("pierre smith", "cancer") → passes if ("pierre smith") and ("cancer") are allowlisted
(‘cancer treatment for 63 years old female in Brussels’) → passes if each token is allowlisted
The threshold is 50 signed-in users whose searches contained the entity during the previous 13 months. For many public or semi-public people, or individuals with names shared by other users in the European Union, that can happen naturally. This also makes it trivial to conduct targeted attacks to make sure every search query related to a chosen person is always revealed in the data set: simply search for their name from 50 different Google accounts.
Once an entity is allowlisted, it remains allowlisted for five years. This turns a name, address, institution, clinic, company, school, or local event label into a long-lived component that will be included in future released queries.
I repeat. All the attacker has to do is to make those 50 searches on 50 signed-in accounts, and then any entity is automatically vetted, practically forever. I’m speaking about the real-world risk here, not the GDPR Data Protection Officer checkbox trainings.
Attack templates
Full-record disclosure through component-level allowlisting
The system enforces thresholds on entities. A query composed of allowlisted entities will be released even if the full query was issued only once.
Example search: ‘John Smith cancer diagnosis’
Turned to entities: ("John Smith", "cancer", "diagnosis")
If each entity is allowlisted (and the above will be, very fast), the full query can be marked as safe, even if only one user ever issued that exact query. The threshold is 50 signed-in users whose searches contained the entity during the previous 13 months. Once ("John Smith") crosses that threshold, it becomes a stable selector for five years (possibly effectively forever).
Example entities:
("Anna Kowalska", "complaint")
("Anna Kowalska", "divorce")
("Anna Kowalska", “clinic")
(“Anna Kowalska”, “BDSM”)
Each such matching query will be collected. The result is a continuous record of what people search about a person, not merely an anonymized statistical count.
Destination-log join
As proposed, the search query feed would contain clicked URLs, click order, click-back buckets, location bucket, device class, access point, language. Imagine an entity that can read not only the search query feed, but also receives data from other sources, for example controls destination websites, buys traffic analytics, operates trackers, or has access to server logs and can join the Search Dataset against external logs. This is suddenly a huge expansion and ability to deanonymise users at scale.
Example:
Imagine a user searches for “stage 3 carcinoma therapy for a 43 yo female” and clicks on a search result taking them to clinic.example.eu/new-treatments/cancer. Today, the destination website can only learn that the visitor came from Google search and doesn’t receive any information about their specific query. Under the EC proposal, the clinic’s logs showing a visit to the given page from the same region, device class, and approximate time window as the query can be reliably linked to the Search Data entry, even though Google removed direct identifiers and precise timestamps.
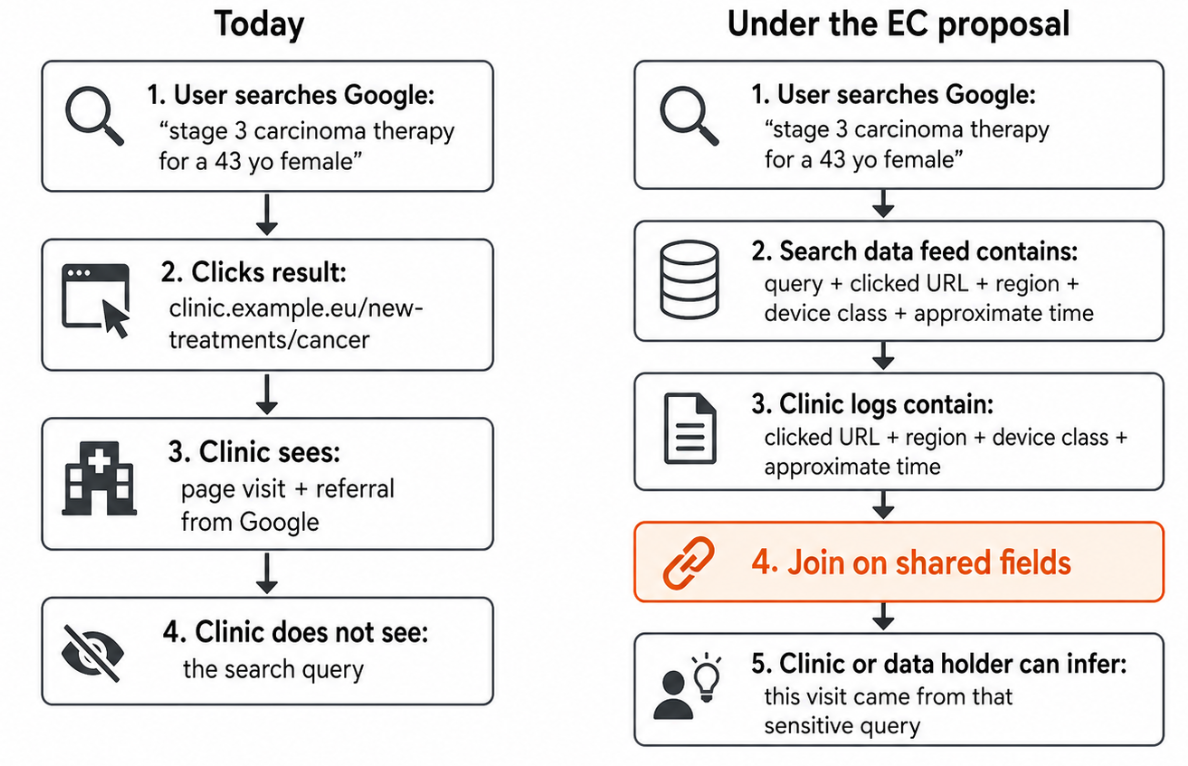
More concerningly, the same attack can be performed by any third-party tracking or analytics script embedded on the destination website. The proposed controls do not structurally prevent this. They prohibit it contractually (paper engineering). Is this fine from the point of view of the European Commission? I mean, it’s them who first proposed the GDPR, and this should violate the risk assessment that Google has to do, in line with the GDPR, assuming that they even do these.
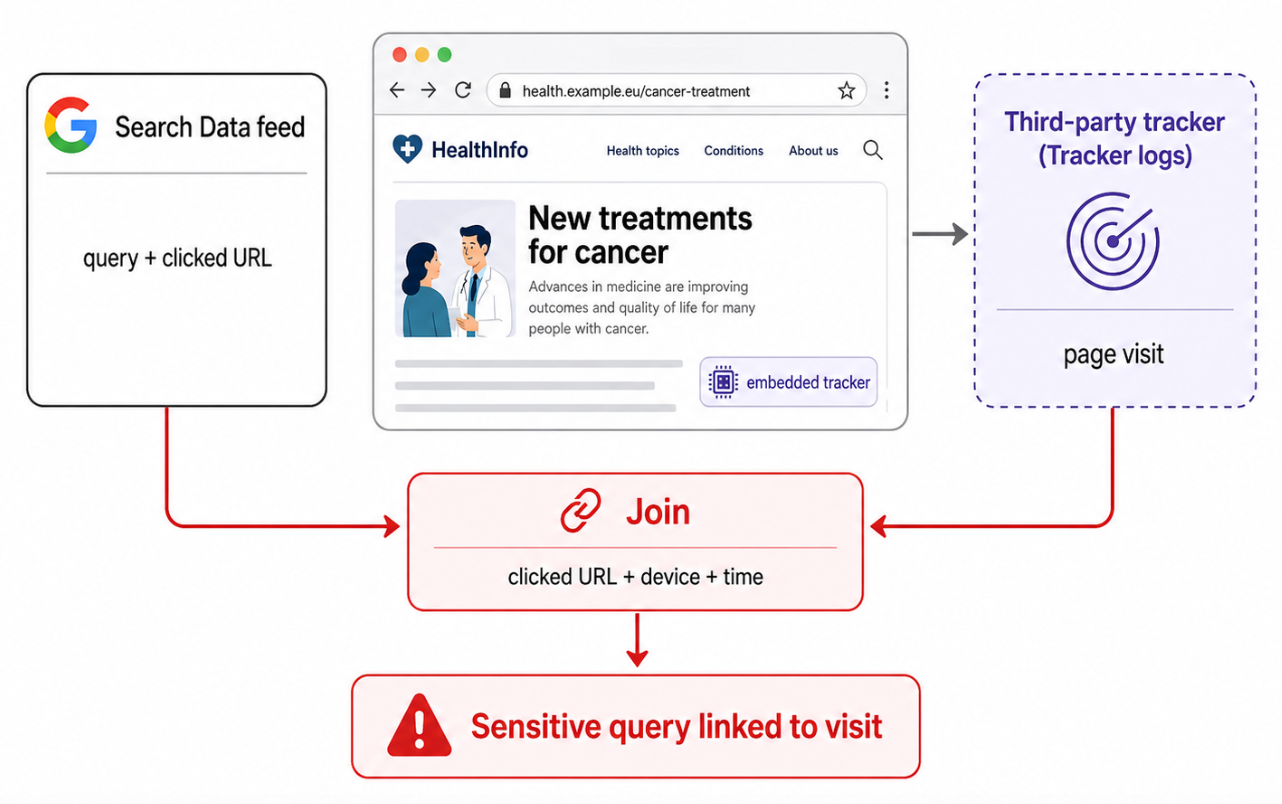
This attack does not depend on the query containing the user's name. It exploits the fact that the same click exists in two systems, and that the data can be joined between these systems
Precise location tracking
This system may enable persistent monitoring of search activity associated with a target’s known home, workplace, institution, or local area. Location is shared as a <country, S2_cell> pair, where the S2 cell must contain at least 1,000 signed-in users and cover at least 3 km². Release requires at least 50 signed-in users sharing the same inferred language, location, and device bucket.
In dense areas, a 3 km² cell can correspond to a few neighbourhood blocks, a hospital district, European Parliament, a government quarter, a university campus, a business park, European Commission, or an area around a court, European Data Protection Supervisor, school, embassy, police facility, or defence contractor. A rural bucket may cover a town, a village.
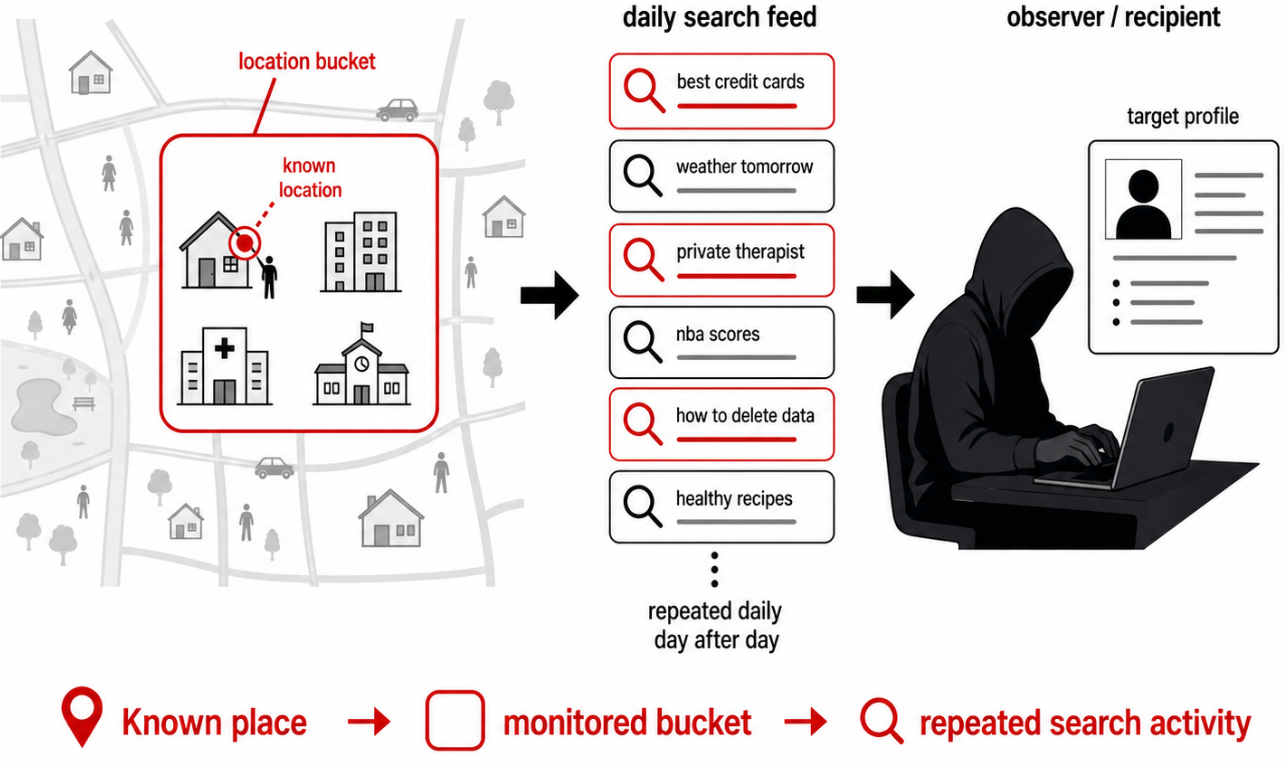
If a target’s home, workplace, school, clinic, or institutional location is known, the recipient can monitor the search feed associated with that area over time. The target’s search traffic is mixed with a small number of other users in the same bucket, but the bucket itself becomes of help here.
The scheme creates area-level search intelligence with daily refresh, enough context. The protection might be fine in Paris or London, but not so fine in other places. Especially with involvement of active, feigned accounts like the ones already mentioned earlier.
National security implications
It gets worse here. The feed has obvious intelligence value. While access is available to entities qualifying as online search engines, including AI systems with search functionality, signing it may be easier than it seems on paper. The gating is paperwork.
A bogus search product, an AI mockup chatbot with web-search functionality may suffice, on paper.
A hostile service could create or fund a formally compliant front company like an AI-search wrapper, a regional search product. Once admitted, it would have a legitimate and reliable channel for monitoring queries around people, objects, institutions, including the ability to target specific victims.

The result is a selector feed. Imagine all those states with an interest with a new intelligence feed selector at a low cost. Not necessarily just China or Russia.
Summary
The scheme releases sensitive data with mock sanitisation that are not adequate for this volume, scale and privacy landscape in 2026.
The threshold of more than 50 signed-in users over 13 months across Europe is so low relative to Google Search scale that, for most terms, it functions more like a filter for absolutely ultra-rare, unique terms than a real privacy safeguard. With hundreds of millions of potential users and a year-long window, even rare terms, symptoms, local names, surnames, slang, drug names, institutions, and niche associations, or in fact word-bricks that may be used to create really sensitive full terms, can easily cross the threshold. The allowlist therefore is not a privacy barrier. It’s more of a procedural formality. Anything that is not extremely unique like “ZNPaUvAp13XDotmHdxwIUkFV0jGwJv05EnHj8ydC”, or correctly detected as rare personal data becomes rubber-stamped as a “safe” component. The fundamental design mistake is that the system confuses frequency of a component with privacy safety of the full query. That threshold of 50, at this scale, creates a false sense of anonymization.
For questions, offers, or inquires, please reach me at me@lukaszolejnik.com